Topic Modeling is a form of statistical/probabilistic modeling used for discovering abstract "topics" from collections of text documents. As more textual information becomes available, topic modeling provides us a way to understand and cluster documents. A document refers to a single body of textual content assumed to cover one or a few topics.
Latent Dirichlet Allocation (LDA) is an example of topic modeling used for analyzing various collections of discrete textual data. In particular, the LDA model aims to uncover underlying distributions of topics per document and words per topic.
- Latent: refers to hidden topic structures
- Dirichlet: refers to the statistical distribution that determines per-document topic distribution and per-topic word distribution
- Allocation: refers to word allocation per topic
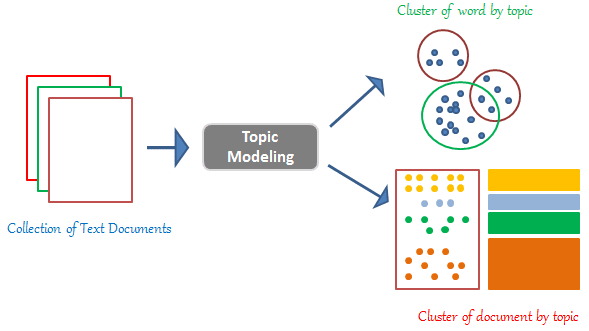
Given 10,000 JSON files consisting of various company data, we aim to infer data content (topics) using the LDA model. Each JSON file is treated as a single document, with file sizes ranging from 105 bytes to 198 KB.
Below is a data sample from a randomly chosen JSON file:
{"user":{
"user_id": "567sad7867asd",
"${EMAIL_ADDRESS.KEY}": "${EMAIL_ADDRESS.VALUE}",
"phone": "${PHONE.VALUE}",
"review_count": 56,
"friends": [
"wqoXYLWmpkEH0YvTmHBsJQ",
"KUXLLiJGrjtSsapmxmpvTA",
"6e9rJKQC3n0RSKyHLViL-Q"
],
...There are several characteristics about the data:
- Every JSON file contains a string representation of a dictionary
- Within the dictionary, there are three types of relationships:
- key:dict --> dict holds properties of key
- key:list --> list holds elements, each an example of key
- key:value --> value is a single example of key
We will extract and encode the keys from the JSON files, including keys in nested dictionaries, before feeding them into the model.
Data Loading and Cleaning¶
# Helper Function for Data Cleaning Dependencies
import re
import os
import string
# Progress bar
from tqdm import tqdm
# Helper Functions for Data Cleaning
def getkeys(file_path):
"""
Code by Luke
Parameter(s)
------------
file_path : str
file path to the JSON file containing string representation of dictionary
Returns
-------
list
contains keys (including any nested key(s)) in the dictionary
"""
assert isinstance(file_path, str), 'file_path must be a string'
file_read = open(file_path, "rb").read()
file_read = file_read.decode("utf-8").encode("ascii", "ignore").decode('ascii')
text = re.sub(r'\"\"', "\"", file_read)
text = re.findall(r'\"[^\"]+\":', file_read)
return [re.sub(r'[\":]', '', t) for t in text]
def parse(word_string):
"""
Code by Yehchan, Amal, Luke, & Amanda
Parameter(s)
------------
word_string : str
string containing words to be parsed
Returns
-------
list
contains lowercase parsed words from word_string
>>> parse('user')
['user']
>>> parse('userid')
['userid']
>>> parse("IPAddress")
['ip', 'address']
>>> parse("user_id")
['use', 'id']
>>> parse("credit.card")
['credit', 'card']
>>> parse("${EMAIL_ADDRESS.KEY}")
['email', 'address', 'key']
"""
assert isinstance(word_string, str), 'word_string must be a string'
space = " "
word_string = re.sub(r'[^a-zA-Z]+', space, word_string)
word_string = re.sub(r"\b([A-Z]*)([A-Z][a-z])", r'\1 \2', word_string)
word_string = re.sub(r"([a-z])([A-Z])", r'\1 \2', word_string)
word_list = word_string.lower().split(space)
return list(filter(lambda s: s, word_list))
def get_doc(folder_path):
"""
Code by Pengyuan & Amanda
Parameter(s)
------------
folder_path : str
folder path to the JSON file containing string representation of dictionary
Returns
-------
list
contains pre-processed (parsed, lowercase) keys from the dictionary
"""
assert isinstance(folder_path, str), 'folder_path must be a string'
prepros_keys = []
for f in tqdm(os.listdir(folder_path)):
full_path = os.path.join(folder_path, f)
key_list = getkeys(full_path)
parsed = []
for k in key_list:
parsed.extend(parse(k))
prepros_keys.append(parsed)
return prepros_keys
file_path = '/content/'
# json_filesnames is a list of 10000 JSON file names for reference
json_filenames = os.listdir(file_path)
assert isinstance(json_filenames, list)
assert isinstance(json_filenames[0], str)
# Showing five JSON file names
json_filenames[:5]
# documents is a list of lists of keys
documents = get_doc(file_path)
assert isinstance(documents, list)
assert isinstance(documents[0], list)
# Showing first ten words of first document
documents[0][:10]
# For flattening list of lists
import itertools
# words is a list of all keys
words = list(itertools.chain(*documents))
#corpus is a single string
corpus = ' '.join(words)
# Data Cleaning Dependencies
!pip install stop_words
from stop_words import get_stop_words
from nltk.stem.porter import PorterStemmer
en_stop = get_stop_words('en')
p_stemmer = PorterStemmer()
# cleaned_texts is a list of lists of strings of cleaned words (each list = doc)
cleaned_texts = []
for text in tqdm(documents):
stemmed = [p_stemmer.stem(word) for word in text if not word in en_stop]
cleaned_texts.append(stemmed)
# cleaned_words is a list of all cleaned words
cleaned_words = list(itertools.chain(*cleaned_texts))
# cleaned_corpus is a single string of cleaned words
cleaned_corpus = ' '.join(cleaned_words)
Exploratory Analysis¶
# EDA/Visualization Dependencies
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import pandas as pd
def create_words_freq(list_of_words):
"""
Code by Amanda
Parameter(s)
------------
list_of_words : list
a list of strings (single words)
Returns
-------
dict
key:value --> word:frequency
"""
assert isinstance(list_of_words, list), 'list_of_words must be a list'
words_pd = pd.Series(list_of_words)
counts = words_pd.value_counts()
words = counts.index
words_and_frequencies = dict()
for word in words:
words_and_frequencies[word] = counts[word]
return words_and_frequencies
# Dictionaries --> word:freq
uncleaned_word_freq = create_words_freq(words)
cleaned_word_freq = create_words_freq(cleaned_words)
# Generating word cloud for entire corpus
wordcloud = WordCloud(max_words = len(cleaned_words),
background_color = 'white',
stopwords = set(),
colormap = 'inferno',
random_state = 42)
wc_entire_corpus = wordcloud.generate_from_frequencies(cleaned_word_freq)
# Plotting Word cloud for entire corpus
plt.figure(figsize = (10, 10))
# Interpolation --> smooth image
plt.imshow(wc_entire_corpus, interpolation = 'bilinear')
plt.title('Word Cloud: Entire Corpus (Cleaned Words)')
plt.axis('off')
plt.show()

Modeling¶
# Modeling Dependencies
from gensim.corpora.dictionary import Dictionary
from gensim.models.ldamodel import LdaModel
from gensim.models import CoherenceModel
# Coherence Visualization Dependencies
import plotly.graph_objects as go
import numpy as np
# Creating dictionary and corpus model inputs
common_dictionary = Dictionary(cleaned_texts)
common_dictionary.filter_extremes(no_below = 100,
no_above = 0.5)
corpus_input = [common_dictionary.doc2bow(text) for text in cleaned_texts]
# Storing models & coherence scores for up to 20 topics
number_topics = list(range(1, 21))
models = []
coherences = []
for num in range(1, 21):
model = LdaModel(corpus_input,
num_topics = num,
id2word = common_dictionary,
random_state=42)
models.append(model)
cm = CoherenceModel(model = model,
texts = cleaned_texts,
corpus = corpus_input,
coherence = 'u_mass')
coherences.append(cm.get_coherence())
# Plotting coherence score vs number of topics
plt.plot(number_topics, coherences)
plt.title('Coherence Score per Number of LDA Model Topics')
plt.xlabel('Number of Topics')
plt.ylabel('Coherence Score')
plt.show()

# topic_nums contains chosen topic numbers
topic_nums = [4, 6, 8, 12, 13, 17, 18]
select_models = [models[n-1] for n in topic_nums]
# Showing model topic distribution with 4 topics
select_models[0].print_topics()
Analysis of Results + More Visualizations¶
# Wordcloud Visualization of Topics
for idx, model in enumerate(select_models):
wc = WordCloud(max_words = len(corpus_input),
background_color = 'white',
stopwords = set(),
colormap = 'plasma')
topics = model.show_topics(formatted=False, num_topics = topic_nums[idx], num_words = 40)
fig, axes = plt.subplots(1, topic_nums[idx], figsize=(20,20), sharex=True, sharey=True)
for i, ax in enumerate(axes.flatten()):
fig.add_subplot(ax)
topic_words = dict(topics[i][1])
wc.generate_from_frequencies(topic_words, max_font_size=300)
plt.gca().imshow(wc)
plt.gca().set_title('Topic ' + str(i+1), fontdict=dict(size=16))
plt.gca().axis('off')
plt.subplots_adjust(wspace=0, hspace=0)
plt.axis('off')
plt.margins(x=0, y=0)
plt.tight_layout()
plt.show()






